
Wie entsteht ein kundenspezifisches System?
Damit das System Gesprochenes verstehen und in Text umwandeln kann, werden mehrere unterschiedliche Erkennungsmodelle genutzt.
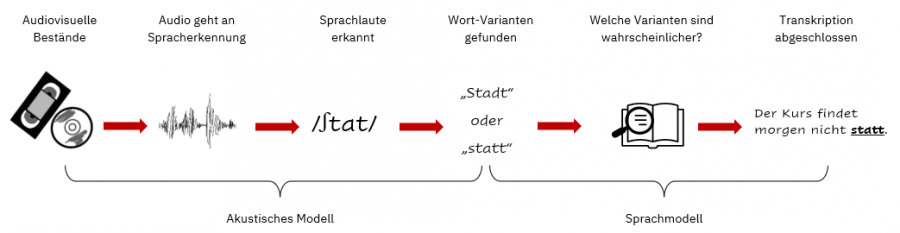
Ein akustisches Modell erkennt einzelne Sprachlaute und fügt sie zu Wörtern zusammen. Das allein ist allerdings nicht ausreichend, da unterschiedliche Wörter oft gleich klingen (siehe Homophone). In der deutschen Sprache ist das bei über 200 Wortpaaren der Fall. Zusätzliche Varianten entstehen durch Dialekte, Akzente und eine undeutliche Aussprache.
Um die korrekte Variante zu bestimmen benötigt man den zweiten Teil vom Prozess – das Sprachmodell.
Vor dem Erkennungsprozess wird das System trainiert. Dabei werden Wortfolgen in einem Text analysiert. Basierend auf der Häufigkeit von Wortfolgen wird eine Wahrscheinlichkeit geschätzt.
Man nennt es das «n-gram»-System. «n» steht hier für die Anzahl der Wörter in einer Wortfolge.
Beispiel:
Der Kurs findet morgen nicht ____
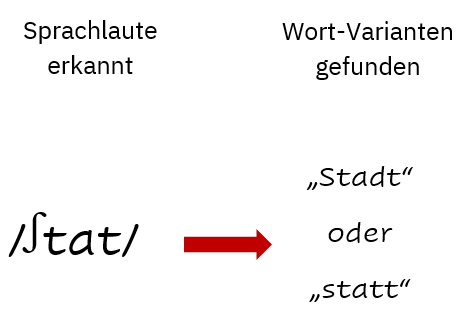
Das System ist sich unsicher über das nächste Wort, da es die gleich tönenden Varianten «Stadt» und «statt» gibt. Das akustische Modell allein sieht beide Wörter als gleich wahrscheinlich.
Um die korrekte Variante zu bestimmen, nutzen wir das Sprachmodell, das oben erwähnte «n-gram»-System. Die Frage ist nun, wie viele Wörter nehmen wir als Kontext?

Die meisten Spracherkennungssysteme nutzen heutzutage ein 4-gram System.
Ohne Kontext hätte man die falsche Variante «Stadt» gewählt, da deren Wahrscheinlichkeit deutlich höher ist. Man benötigt eine Wortfolge, um die richtige Variante zu erkennen.
Um die Wahrscheinlichkeiten möglichst realitätsnah bestimmen zu können, benötigt das System grosse Mengen an Textmaterial.
Deswegen ist es wichtig, dass Sie uns Ihr Spezialvokabular in Textform zukommen lassen. Je mehr Text, in welchem Ihre Fachbegriffe und Eigennamen erwähnt werden, desto besser!